Jak přidat agentního AI chatbota na svůj web (RAG návod)
Chcete si na svůj web přidat chatbota, který posílá emaily, domlouvá schůzky a zná celý váš web nazpaměť? Přečtěte si více v článku.
Chcete na webu chatbota, který skutečně zná vaše produkty, služby, ceníky nebo dokumentaci a neodpovídá jen obecné fráze? V tomto článku vás provedu tvorbou “agentního” chatbota sestrojeného pomocí nástroje n8n. Ukážeme si, jak využít metodu RAG k propojení AI s vašimi daty z webu a jak agentovi umožnit provádět akce, jako je odesílání e-mailů či domlouvání schůzek.
Obsah článku:
- Co znamená RAG a proč ho chtít
- Jak si vytvořit vlastního chatbota a přidat ho na svůj web
- Shrnutí: Jak to celé funguje v bodech
- Na co si dát pozor
Co znamená RAG a proč ho chtít
Ještě něž se dostaneme k samotné tvorbě, je potřeba pochopit klíčový koncept, bez kterého by nám model nedával relevantní odpovědi. Tím je RAG.
Zkratka RAG (Retrieval-Augmented Generation) se překládá do češtiny jako generování rozšířené o vyhledávání. Jedná se o koncept, díky kterému váš AI model “nehalucinuje” (nevymýšlí si), ale odpovědi generuje na základě nějaké znalostní databáze, kterou mu vy sami předložíte.
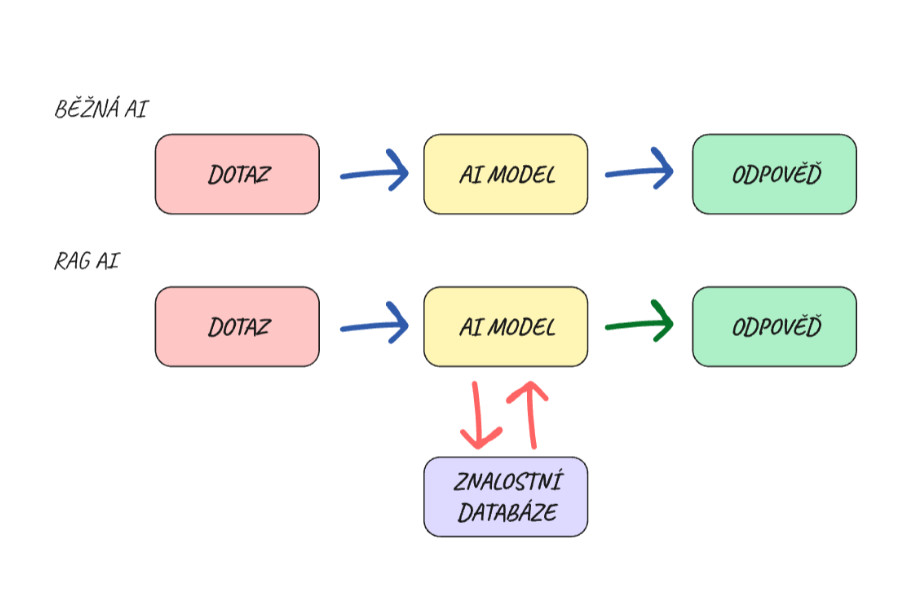
Běžný AI model je jako velmi vzdělaný člověk, který však od určitého data přestal sledovat novinky a nezná nic o vašem konkrétním byznysu. Když se ho zeptáte na něco z interní dokumentace, nebude vědět a může si i vymýšlet. Pokud tomu samému člověku dáte do ruky vaše materiály (ceník, dokumentaci, články, FAQ) a řeknete mu: “Odpovídej pouze na základě toho, co zde najdeš.”, najde tu správnou odpověď. Takto velmi zjednodušeně funguje RAG AI Model.
Jak RAG proces vypadá v praxi:
- Příprava dat: Dokumenty očištěné o duplicity a nepotřebný obsah se rozsekají na menší části. Tyto kousky se pomocí embedding modelu převedou na vektory a uloží do speciální vektorové databáze, kde v nich AI umí efektivně hledat dle kontextu.
- Zpracování dotazu: Když se uživatel zeptá, systém převede jeho dotaz pomocí stejného modelu na vektor a najde nejbližší kontextovou shodu v databázi. Vytáhne tak pouze ty odstavce, které s otázkou souvisí.
- Generování odpovědi: Tyto vybrané odstavce se přibalí k původní otázce a pošlou se LLM modelu, který z nich sestaví finální odpověď. Do odpovědi tedy nejsou zahrnuty pouze znalosti natrénované v LLM modelu, ale i nalezené informace.
Jak si vytvořit vlastního chatbota a přidat ho na svůj web
Způsobů, jak si sestrojit chytrý AI chat a umístit ho na vašem webu, je hned několik. Velmi jsem si oblíbil low-code automatizační nástroj n8n, kde můžete hezky vizuálně vidět, jak informace ve workflow putují z jednoho uzlu do druhého. Budu tedy popisovat implementaci právě s tímto nástrojem.
Pro vás neznalé, n8n je taková virtuální stavebnice Merkur, jen pro automatizace. Má v sobě přímo integrované stavební bloky LangChain, takže v něm lze vytvářet komplexní agentní systémy bez napsání jediného řádku kódu.

Co budeme potřebovat:
- n8n - Centrální mozek. Orchestruje workflow a poskytuje chatovací rozhraní pro uživatele na pokládání dotazů a dávání pokynů.
- Vektorová databáze - Místo, kam uložíme vlastní data v podobě, které AI rozumí.
- Embedding model - Nástroj, který převede váš lidský text na číselné vektory.
- Napojení na LLM model - Předtrénovaný AI model (Gemini, Chat GPT, lokální LLM …), který dává agentovi schopnost rozumět a generovat text.
- Paměťová databáze – Databáze sloužící k tomu, aby si agent pamatoval, co uživatel napsal před minutou.
- Google účet - Pro integraci s Gmailem (odesílání e-mailů), Google Diskem (čtení dokumentů) a Google Kalendářem (domlouvání schůzek).
Teorii máme za sebou, pojďme si tedy vyhrnout rukávy a podívat se na to, jak tyto koncepty přetavit v realitu. Ani nemusíte být programátor, abyste vytvořili funkční systém, který dává smysl. Stačí pochopit, jak správně pospojovat jednotlivé stavební bloky od databáze až po samotné chatovací okno.
Zajímá vás, kolik stojí provoz takového chatbota? Napište mi zprávu nebo si se mnou domluvte 30 min konzultaci ZDARMA, kde to spolu můžeme probrat :)
Krok 1. Příprava dat a uložení do vektorové databáze
V mém případě chci, aby měl AI agent kontext celého webu. Musím tedy nějakým způsobem dostat informace z webu do vektorové databáze, odkud si bude LLM model brát informace ke zpracování odpovědí. Použijeme k tomu data ze sitemapy. Stáhneme z ní url adresy stránek na webu, převedeme je z XML formátu do JSONu.
Poté načteme obsah jednotlivých stránek přes GET HTTP požadavek a očistíme o přebytečný balast. Nepotřebujeme totiž celou strukturu webu jako je hlavička nebo patička. Nakonec převedeme výsledný HTML obsah do Markdown formátu, kterému AI modely lépe rozumí. A máme vstupní data z webu připravená.
Jaká další data můžete svému AI agentovi předhodit? Vstupní data můžete doplnit například soubory ze svého Google Disku jako jsou PDF soubory, tabulky, textové dokumenty apod. Důležité je však vždy myslet na bezpečnost citlivých dat a krmit agenta jen tím, co ke své roli skutečně potřebuje. Pamatujte, že s rostoucím množstvím a komplexitou dat roste i potřeba data řádně očišťovat a optimalizovat RAG pro rychlé a přesné odpovědi.
Nyní můžeme vyčištěná data uložit do vektorové databáze, odkud si bude AI agent brát informace pro sestavení relevantních odpovědí. Do vektorové databáze však nelze uložit text jen tak napřímo. Aby v něm AI mohla efektivně vyhledávat, musí být text nejdříve převeden na digitální otisk (vektor). K tomu slouží již výše zmíněné embedding modely.
Před finálním uložením do vektorové databáze se text ještě musí rozdělit na menší celky, tzv. “chunking”. Jde o to, aby se modelu ke zpracování nepředhodily 42-stránkové obchodní podmínky e-shopu (které stejně nikdo nečte) najednou, ale pouze její menší celky relevantní vůči dotazu. Tím se zásadně šetří kontextové okno modelu a s tím související náklady na tokeny, za jejichž spotřebu se platí.
Obvykle se velikost jednoho kousku (“chunku”) pohybuje mezi 500-1000 znaky s překryvem 10-20%. Tento překryv je klíčový, aby se při rozdělení textu neztratil kontext a myšlenka plynule navazovala i v dalším bloku. Samotné rozdělování pak probíhá podle logických pravidel, nejčastěji podle odstavců nebo nadpisů.

Do vektorové databáze tedy ukládáme data ideálně očištěná a rozsekaná na menší části. Abychom neztratili kontext, odkud data pocházejí, doplníme do metadat URL adresu a datum poslední aktualizace dané webové stránky. Agent pak může v odpovědi uvést odkaz, odkud čerpal, což zvyšuje jeho důvěryhodnost a dotazující si může odpovědi rovnou ověřit na konkrétním odkazu.
Krok 2. Sestavení Agenta s jeho nástroji
V n8n propojíme AI Agenta s naší vektorovou databází. Tím získá svou dlouhodobou paměť ze zdrojů, které jsme mu předem uložili. Aby si agent pamatoval, co uživatel napsal před minutou, je potřeba mu také přidat krátkodobou paměť, kam se bude ukládat historie společné konverzace.
Nyní bychom měli RAG AI Chatbota, ale stále ještě bychom mu nemohli říkat agentní chatbot. Co dělá z obyčejného chatbota skutečný agentem je právě schopnost jednat v reálném čase. V tomto případě mu přidáme nástroj, kterým může odesílat emaily z našeho Gmailového účtu. Můžeme mu také přidat přístup do kalendáře, aby věděl, v jakých časech jsou volné sloty pro domluvení schůzky a schůzku poté zapsat do kalendáře.
Pokud bychom chtěli, mohli bychom mu dát přístup k vyhledávání na internetu nebo napojení na různé externí API, ať už jde o počasí, měnové kurzy či stavy eshopových objednávek, či se v reálném čase dotazovat na zákazníky přímo do svého CRM.
Krok 3. Optimalizace systémového promptu, důkladné testování a re-ranking
Nejdůležitější částí je definice systémového promptu. Jde o sadu instrukcí, která definuje osobnost, cíle a mantinely agenta. Nesmíme zapomenout nadefinovat i to, jak má používat připojené nástroje. Jakmile jsme spokojení s pokyny pro AI Agenta, začneme testovat. Budeme testovat relevanci odpovědí a chování podle namyšlených scénářů.
Když zjistíme, že agent odpovídá nepřesně, máme několik možností, co s tím udělat. Můžeme např. upravit systémový prompt, vyzkoušet jiný AI model nebo zpřesnit výběr dat z vektorové databáze pomocí tzv. Re-rankingu.
Re-ranking model funguje jako druhý, přísnější filtr. Znovu a důkladněji projde výsledky z databáze a seřadí je podle skutečné relevance k dotazu. Teprve ty nejlepší kousky informací pošle finálnímu modelu k vypracování odpovědi. V našem konkrétním případě však není re-ranking nezbytně nutný vzhledem k menšímu objemu vstupních dat, ale je dobré o něm vědět, jakmile váš systém začne růst.
Krok 4. Automatická aktualizace dat
Vytvoříme workflow, která bude automaticky jednou za čas (např. 1x denně o půlnoci) aktualizovat data ve vektorové databázi, aby vždy odpovídala aktuálnímu stavu informací na webu.
Krok 5. Přidání chatovacího okna na web
Interakce s AI agentem bude probíhat pomocí chatovacího okna, které umístíme do kódu na našem webu. Nativní chatovací okno má už v sobě n8n integrované, takže není nutné si psát vlastní chatovací rozhraní či používat aplikaci 3. strany. Vyzkoušíme, zda vše chodí, jak má. Nezapomeneme přidat svoji webovou stránku do CORS.
Vyzkoušejte si chatbota přímo na mém webu Pokláboste s Dankou - mojí virtuální asistentkou - přímo teď a tady. Vpravo dole by měla být umístěná bublina s chatem. Nebojte se vyzkoušet, jak na vás bude Danka reagovat. Klidně mi můžete poslat zpětnou vazbu emailem přímo skrz chatovací okno.
Shrnutí: Jak to celé funguje v bodech
V momentě, kdy uživatel odešle dotaz, proběhne v n8n tento řetězec událostí:
- Analýza záměru: AI zjistí, zda se uživatel ptá na informaci, nebo chce něco zařídit, např. odeslat vzkaz či domluvit schůzku.
- Pokud jde o dotaz na znalostní databázi:
- Vyhledání: Agent prohledá vektorovou databázi.
- Zpřesnění: Vybere ty nejrelevantnější kousky informací.
- Pokud jde o akci:
- Akce: Jestliže uživatel chce např. zanechat vzkaz, agent použije emailový nástroj pro odeslaní zprávy. Pokud však nemá vše, co potřebuje, k odeslání emailu, doptá se na zbývající informace v dalším kroku.
- Generování odpovědi: AI složí srozumitelnou odpověď kombinující data z databáze.
Na co si dát pozor
- Kvalita a zpracování vstupních dat - RAG je jen tak dobrý, jak dobrá jsou vaše zdrojová data. Mějte vždy data aktuální, dobře strukturovaná a ošetřená od duplicit či nepotřebných informací.
- Bezpečnost dat a soukromí - Nastavte agentovi jasné hranice, k jakým datům smí přistupovat. Vzhledem k citlivosti údajů je potřeba se zamyslet nad tím, odkud a kam data posíláte a kdo s nimi může nakládat (GDPR). Taky je potřeba mít na paměti, že většinou bezplatné LLM modely souvisí s trénováním modelu na vašich datech. V některých případech je potřeba zvážit, zda nepoužít svůj vlastní lokální model (např. přes Ollama), čímž zajistíte, že data nikdy neopustí váš vlastní server. Pokud nemá model v základu ochranu proti pokusům o zneužití přes tzv. prompt injection, implementujte tuto ochranu do systémového promptu.
- Cena a efektivita - Sledujte spotřebu tokenů. Pro agentní systémy jsou spolehlivější dražší modely, ale ne vždy je nutné střílet z kanonu na vrabce. Pro jednodušší úkoly můžete zkusit levnější modely a ušetřit tak značné náklady. Hlídejte si také limit iterací, aby se agent při hledání odpovědi nezacyklil a zbytečně nevyčerpal váš rozpočet.
- Human-in-the-loop - U kritických akcí, jako je odesílání důležitých e-mailů nebo mazání dat v CRM, nenechávejte AI zcela o samotě. Přidejte schvalovací krok člověkem, abyste předešli nevratným chybám.
- Logování a monitoring - Logování je váš nejlepší nástroj pro následnou optimalizaci systému.
V tomto článku jsem nezacházel do přílišných detailů ohledně samotné stavby workflow v rámci n8n. Cílem bylo poskytnout vám, čtenářům, představu o tom, jak funguje RAG a jak si každý může vytvořit vlastního agentního AI chatbota.
Chcete vlastního chatbota na svém webu, ale nevíte si s tím rady? Napište mi zprávu nebo si se mnou domluvte 30 min konzultaci ZDARMA.